

ソース:https://www.zerohedge.com/political/meta-accused-using-pirated-books-train-ai-authors-are-pissed
マーク・ザッカーバーグが再び厳しい批判にさらされています。今回は、Metaが最先端のAIモデル「Llama 3」の訓練用に、悪名高いデジタル海賊版サイト「LibGen」と「Anna’s Archive」から意図的に数百万冊の本を盗用したという爆弾告発に直面しています。
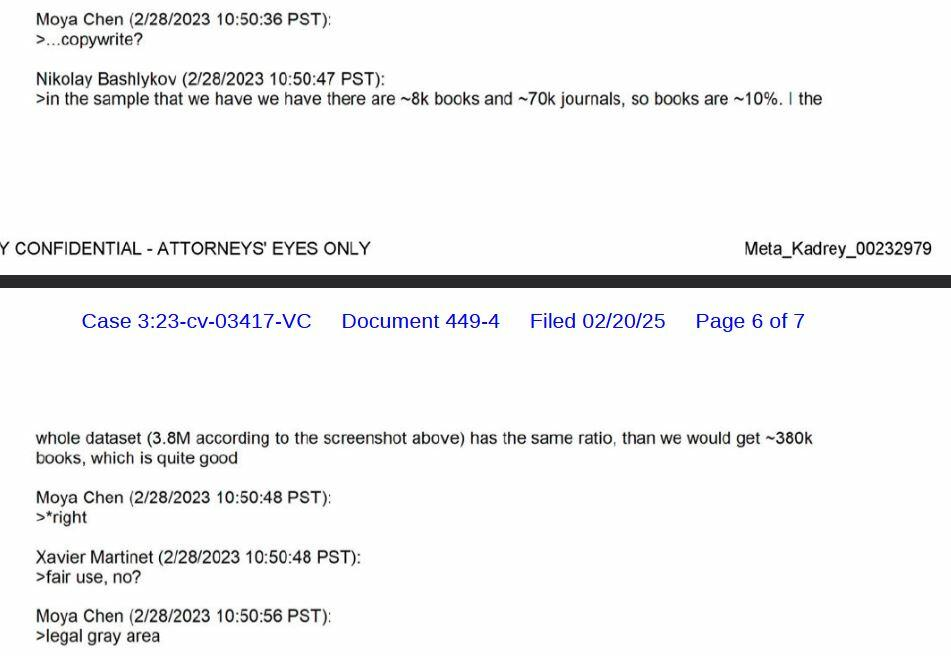
先日提出された裁判所文書によると、Metaの経営陣は、質の高いコンテンツを切実に必要としていることを公然と話し合っていたとされています。「書籍は実際にはウェブデータよりも重要である」という痛烈な内容の電子メールも確認されています。その目的のために、同社は盗まれた文学の至宝が山積みされた海賊版の温床に真っ先に目を付けたとForbes誌は報じています。
Metaのスタッフは、そのギャップを埋めるために、750万冊以上の海賊版書籍と8100万以上の盗難研究論文を所蔵するLibGenに目を向けました。彼らはアンナのアーカイブについても同様の対応を行いました。
…
先日提出された裁判書類によると、創設者兼CEOのマーク・ザッカーバーグ氏が率いるMetaは、意図的に明確にLibGen(および、もうひとつの巨大なデジタル海賊版の温床であるAnna’s Archive)への強制捜査を許可し、最新のAIモデルであるLlama 3の訓練に利用したと疑われている。
この騒動は世界中の作家を激怒させました。彼らのライフワークが、クレジット、同意、または補償なしに、ひっそりとザッカーバーグの最新の技術的傑作に利用された可能性があるからです。
記事にもあるように、Metaの2024年の財務諸表では、収益が1640億ドルを上回り、利益は620億ドルに迫っています。 明確に、Metaには、クリエイター、パブリッシャー、研究者らに正当な補償を行う手段と能力がありました。 それにもかかわらず、彼らはそのコンテンツをトレーニング目的で盗むことを選択したとされています。
評論家たちは、この物語は単なる企業の強欲以上のものだと主張しています。
彼らはLLMの入力データにおけるリーダーとして行動し、著者の権利を尊重するライセンス契約を結んだかもしれません。もしその会社が、社会における最新の最重要問題のひとつについてリーダーとなる企業文化を持っていたらどうなっていたでしょうか。LLMのコンテンツの所有者は誰か?
偶然にも、Metaの「長期的な影響に焦点を当てる」という基本理念には、「目先の利益を最適化するのではなく、長期的な視野に立って、当社が及ぼす影響のタイムラインを拡大することを重視する」と明記されています。
Metaがこのケースでは、コラボレーションと信頼性を重視する企業文化とリーダーシップの立場を打ち出すのではなく、実際には目先の利益を最適化していたことは、非常に明確に示されています。
一方、Metaの弁護側は「公正使用」の主張に依存しており、同社のAIは盗まれたコンテンツを十分に新しいものに変換していると主張しています。しかし、法律の専門家は、公正使用は通常、教育者、批評家、評論家に適用されるものであり、大量の商業データを収集して利益を得ている1兆ドル規模の巨大テクノロジー企業には適用されないと強調しています。
Forbesの記事の著者は、The Atlanticのアレックス・ライズナー氏のLibGen追跡ツールを確認し、不穏な発見をしました。同氏が出版した5冊の書籍すべてが海賊版として発見され、Metaのデータセットに含まれていたのです。
著者の言葉を借りれば、「他の企業も同様の罪を犯している可能性が高い」という著作権侵害と不正競争を理由に、大規模な集団訴訟が提起されました。
最終的には、この問題はMeta社だけに留まりません。AI業界全体が抱えるデータに対する飽くなき渇望には、明確な倫理的なガードレールが早急に必要です。テクノロジー大手企業は、コンテンツ制作者と持続可能で公正なパートナーシップを結ぶか、さもなければ創造性を抑制し、知的財産権を損ない、社会の信頼を損なうリスクを負うことになります。


{kind=link}
{kind=link}
コメント