

H100価格の高騰、補助金付き推定価格、輸出規制、MLA
ソース:https://semianalysis.com/2025/01/31/deepseek-debates/
DeepSeekによる物語が世界を席巻
DeepSeekは世界中で大きな話題となりました。先週から、DeepSeekは世界中の誰もが話題にしたがる唯一のトピックとなっています。現状では、DeepSeekのデイリー・トラフィックは、Claude、Perplexity、さらにはGeminiよりもはるかに多くなっています。
しかし、宇宙の動向を注視している人々にとっては、これは「新しい」ニュースではありません。私たちは数ヶ月間、DeepSeekについて話し続けてきました(各リンクがその例です)。この会社は新しいものではありませんが、執拗なまでの宣伝は新しいものです。SemiAnalysisは以前から、DeepSeekは非常に優れた能力を持っていると主張してきましたが、米国の一般市民は関心を示しませんでした。世界がようやく注目し始めたとき、それは現実を反映していない執拗なまでの宣伝によってでした。
先月、スケーリングの法則が破られたとき、私たちはこの神話を払拭しました。そして今、アルゴリズムの改善が速すぎるため、これもまたNvidiaとGPUにとって悪いことであるかのように見えます。
現在の説明では、DeepSeekは非常に効率的であるため、これ以上のコンピューティングは必要なく、モデルの変更により、現在はすべてに大幅な過剰供給能力があるとしています。Jevonsのパラドックスも誇張され過ぎているとはいえ、Jevonsの方が現実に近いと言えます。モデルはすでにH100とH200の価格設定に目に見える影響を及ぼす需要を誘発しています。
DeepSeekとHigh-Flyer
High-Flyerは、中国系のヘッジファンドであり、取引アルゴリズムにAIを導入した初期の企業です。同社は、金融以外の分野におけるAIの潜在的可能性と、スケーリングの重要な洞察力を早期に認識していました。その結果、GPUの供給量を継続的に増やしてきました。数千のGPUクラスタを使用したモデルの実験を経て、High Flyerは輸出規制が実施される前に、2021年に10,000台のA100 GPUに投資しました。その投資は実を結びました。High-Flyerの業績が向上するにつれ、2023年5月には、より焦点を絞ったAI能力の追求を目的として「DeepSeek」をスピンオフさせる時期が来たことを認識しました。外部投資家がAIにほとんど関心を示さなかったため、ビジネスモデルの欠如が主な懸念事項であった当時、High-Flyerは自社で資金調達を行いました。今日、High-FlyerとDeepSeekは、人的および計算リソースを共有することがよくあります。
DeepSeekは現在、真剣かつ組織的な取り組みへと成長しており、メディアで主張されているような「副次的なプロジェクト」などではありません。輸出規制を考慮しても、彼らのGPUへの投資額は5億米ドルを超えると確信しています。

GPUの状況
彼らは約50,000個のHopper GPUにアクセスできると当社は考えていますが、これは一部で主張されているような50,000個のH100とは異なります。Nvidiaは、さまざまな規制に準拠してH100の異なるバリエーション(H800、H20)を製造しており、現在、中国のモデル・プロバイダーが利用できるのはH20のみです。H800はH100と同じ演算能力を持ちますが、ネットワーク帯域幅は低くなります。
DeepSeekは、これらのH800を約10,000台、H100を約10,000台保有していると当社は考えています。さらに、Nvidiaは過去9か月間で100万個以上の中国専用GPUを生産しており、DeepSeekはさらに多くのH20を発注しています。これらのGPUはHigh-FlyerとDeepSeekで共有され、ある程度地理的に分散されています。これらのGPUは取引、推論、トレーニング、研究に使用されています。より詳細な分析については、当社のアクセラレータモデルをご参照ください。
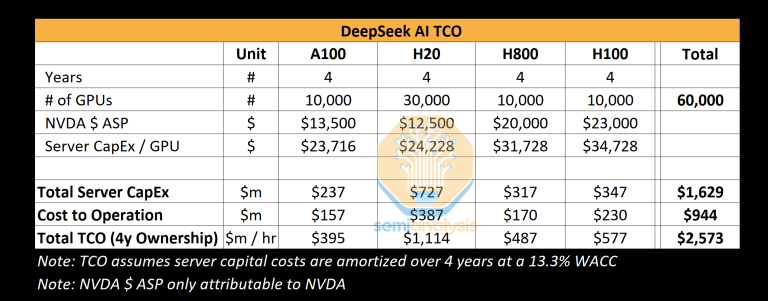
当社の分析では、DeepSeekのサーバー関連の資本的支出は総額で約16億ドルに達し、このようなクラスターの運用には9億4400万ドルの相当なコストがかかっています。同様に、AIラボやハイパースケーラーは、研究やトレーニングなど、さまざまなタスクに多くのGPUを使用していますが、リソースの集中管理が課題となっているため、個々のトレーニング実行にGPUを割り当てることはできません。X.AIは、すべてのGPUを1か所に集約している点で、AIラボとしてはユニークです。
DeepSeekは、過去の経歴は問わず、能力と好奇心に重点を置いて、中国国内から人材を確保しています。同社は、多くの社員が卒業した北京大学や浙江大学などの一流大学で定期的に採用イベントを開催しています。職務は必ずしも事前に定義されているわけではなく、採用には柔軟性が与えられており、求人広告では、使用制限のない1万以上のGPUへのアクセスを誇っています。彼らは非常に競争力があり、有望な候補者には130万ドル以上の給与を提示していると言われています。これは、中国の大手テクノロジー企業や、MoonshotのようなAIラボをはるかに上回る額です。彼らは約150人の従業員を抱えていますが、急速に成長しています。
歴史が示すように、資金が潤沢で、明確な目標を持つ小規模な新興企業は、しばしば不可能を可能にするのです。DeepSeekはGoogleのような官僚主義がなく、自己資金で運営されているため、アイデアを迅速に実行に移すことができます。しかし、Googleと同様に、DeepSeekは(ほとんどの場合)外部の業者やプロバイダーに頼らず、独自のデータセンターを運営しています。これにより、さらなる実験の余地が生まれ、スタック全体にわたって革新をもたらすことができるのです。
私たちは、彼らが今日のラボにおける最高の「オープン・ウェイト」であると信じています。Metaの「Llama」や「Mistral」、その他のものよりも優れています。
DeepSeekの費用対効果
今週、DeepSeekの価格と効率性が話題となり、主な見出しはDeepSeek V3のトレーニング費用「600万ドル」という数字でした。これは誤りです。これは、ある製品の部品表の特定の部分を指して、それを全体のコストであるかのように主張するようなものです。事前トレーニング費用は、総コストのごく一部にすぎません。
トレーニング費用
事前トレーニングの数値は、モデルに実際に費やされた金額のどこにも該当しないと私たちは考えています。 彼らのハードウェアへの投資額は、会社設立以来、5億ドルをはるかに超えていると確信しています。 新しいアーキテクチャのイノベーションを開発するには、モデル開発中に、新しいアイデア、新しいアーキテクチャのアイデア、および削除について、相当なテスト費用がかかります。 DeepSeekの主要なイノベーションであるマルチヘッド・ラテン・アテンションの開発には数か月を要し、チーム全体の人件費とGPU時間コストがかかりました。
論文で600万ドルとされているコストは、事前トレーニング実行のGPUコストのみに起因するものであり、モデルの総コストの一部に過ぎません。ハードウェア自体の研究開発や総所有コスト(TCO)といった重要な要素は除外されています。参考までに、Claude 3.5 Sonnetのトレーニングには数千万ドルの費用がかかりました。もしAnthropic社が同様の費用を必要としたのであれば、Googleから数十億ドル、Amazonから数百億ドルを集めることはできなかったでしょう。なぜなら、実験を行い、新しいアーキテクチャを考案し、データを収集・クリーンアップし、従業員に給与を支払うなど、他にも多くの作業が必要だからです。
では、DeepSeekはどのようにしてこれほど大規模なクラスタを構築できたのでしょうか?輸出規制の遅れが鍵であり、以下の輸出セクションで説明します。
ギャップを埋める – V3のパフォーマンス
V3は間違いなく素晴らしいモデルですが、素晴らしいのは相対的に何に対してかを強調する価値があります。V3をGPT-4oと比較し、V3が4oのパフォーマンスを上回ることを強調する人も多くいます。確かにその通りですが、GPT-4oは2024年5月にリリースされました。AIの進化は早く、2024年5月はアルゴリズムの改善においては、また別の昔のことです。さらに、一定の期間が経過した後、同等の、あるいはより優れた能力を達成するために必要な計算量が少なくなることは驚くことではありません。推論コストの低下は、AIの改善の顕著な特徴です。
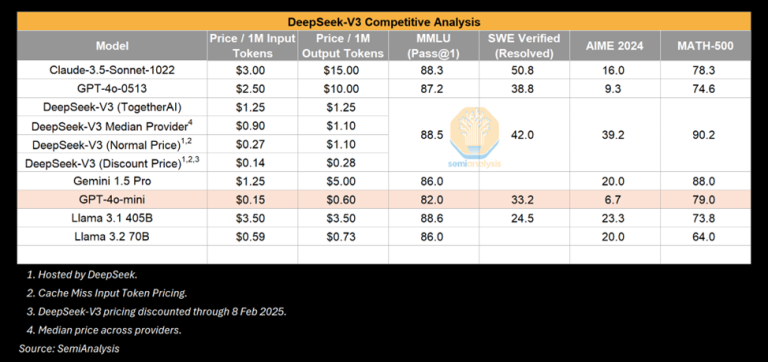
例えば、ノートパソコンで実行できる小さなモデルでも、トレーニングにスーパーコンピューターを必要とし、推論に複数のGPUを必要としたGPT-3と同等の性能を発揮できます。言い換えれば、アルゴリズムの改善により、同じ能力を持つモデルのトレーニングと推論に、より少ない量のコンピューティングで対応できるようになり、このパターンが何度も繰り返されています。今回は、中国にある研究所によるものだったため、世界が注目しました。しかし、小さなモデルが改善されることは新しいことではありません。
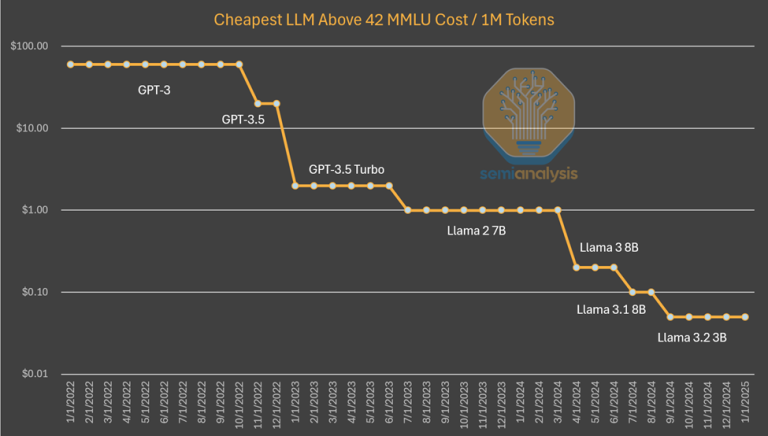
このパターンでこれまでに私たちが目撃したことは、AIラボは、より多くの知能を獲得するために、絶対的なドルでより多くを費やしているということです。アルゴリズムの進歩は年率4倍であると推定されており、つまり、年を追うごとに同じ能力を達成するために必要な演算能力は4分の1ずつ少なくなっているということです。AnthropicのCEOであるダリオは、アルゴリズムの進歩はさらに速く、10倍の改善をもたらす可能性があると主張しています。GPT-3レベルの推論価格については、コストは1200分の1にまで低下しています。
GPT-4のコストを調査すると、曲線上では初期の段階ですが、同様のコスト削減が見られます。時間経過によるコストの差異の減少は、上図のように能力を一定に保たなくなったことによって説明できます。このケースでは、アルゴリズムの改善と最適化により、コストが10分の1に削減され、能力が向上しています。
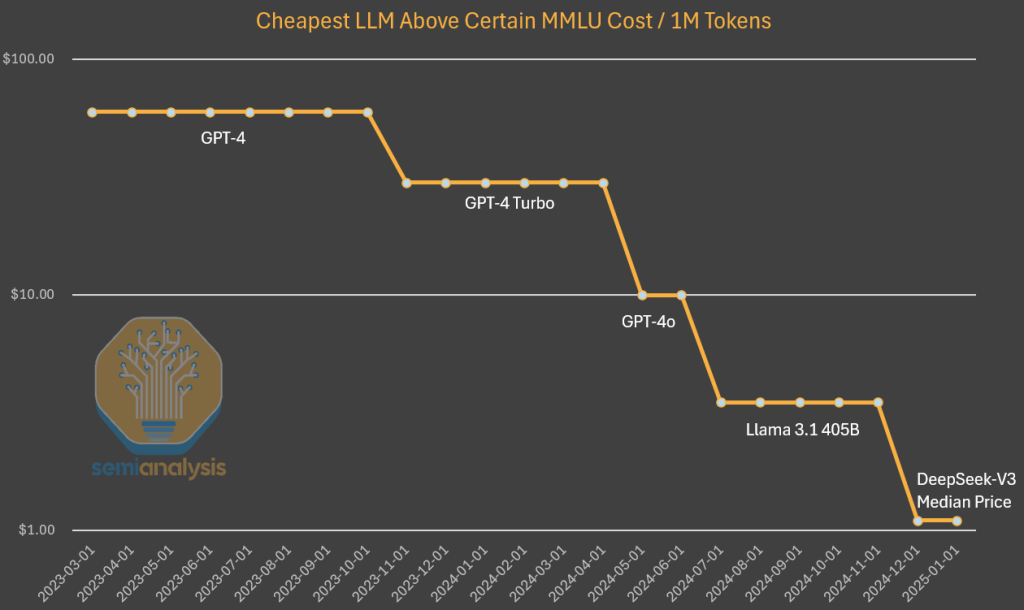
はっきりさせておくと、DeepSeekは、このレベルのコストと性能を最初に実現したという点でユニークです。オープンウェイトをリリースしたという点でもユニークですが、MistralやLlamaの以前のモデルでも同様のことを行なってきました。DeepSeekは、このレベルのコストを実現しましたが、今年末までにコストがさらに5分の1に下がっても驚かないでください。
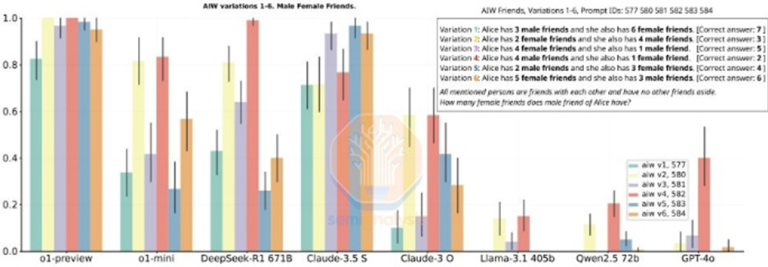
R1のパフォーマンスはo1のパフォーマンスに匹敵するのか?
一方、R1はo1と同等の結果を出すことができ、o1は9月に発表されたばかりです。DeepSeekはなぜこれほど急速に追いつくことができたのでしょうか?
その答えは、推論は、以前のパラダイムよりも少ない量の演算で、より高速な反復速度とより大きな成果をより簡単に得られる新しいパラダイムであるということです。当社のスケーリングの法則に関するレポートで概説しているように、以前のパラダイムは事前トレーニングに依存しており、それはより高価になり、堅牢な成果を達成することが難しくなっています。
合成データ生成と既存モデルのポストトレーニングにおけるRLによる推論能力に焦点を当てた新しいパラダイムは、より低コストでより迅速な利益をもたらします。参入障壁が低く、最適化が容易であるため、DeepSeekは通常よりも早くo1メソッドを再現することができました。プレイヤーがこの新しいパラダイムでよりスケールする方法を理解するにつれ、マッチング能力の時間差は拡大すると予想されます。
R1の論文では使用されたコンピューティングについては言及されていません。これは偶然ではありません。R1のポスト・トレーニング用の合成データを生成するには、膨大な量のコンピューティングが必要だからです。これはRLについては言わずもがなです。R1は非常に優れたモデルであり、これについては異論はありません。そして、これほど短期間で推論エッジに追いついたことは客観的に見ても素晴らしいことです。DeepSeekは中国企業であり、より少ないリソースで追いついたという事実が、その素晴らしさを倍増させています。
しかし、R1が言及しているベンチマークの中には誤解を招くものもあります。R1とo1を比較するのは難しいです。なぜなら、R1は特に、自分がリードしていないベンチマークについては言及していないからです。R1は推論性能ではo1に匹敵しますが、すべての指標で明確な勝者というわけではなく、多くの場合、o1よりも劣ります。
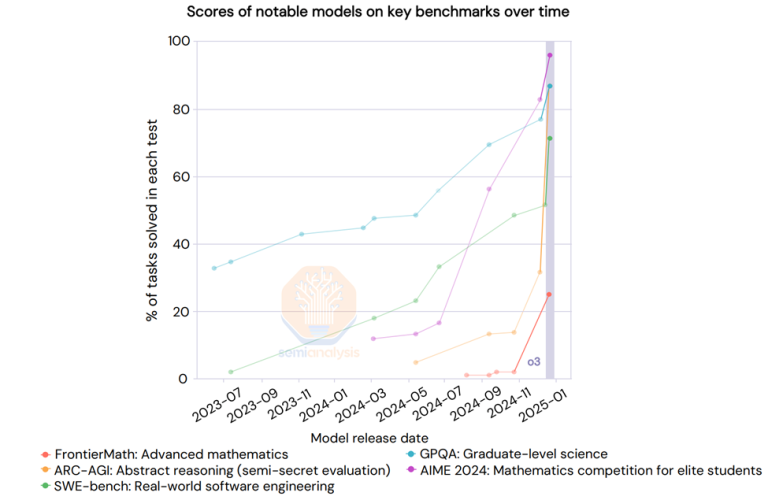
そして、o3についてはまだ触れていません。o3はR1やo1よりもはるかに高い能力を持っています。実際、OpenAIは最近、o3の成果を共有しており、ベンチマークのスケーリングは垂直です。「ディープ・ラーニングは壁にぶち当たった」が、それは異なる種類のものです。
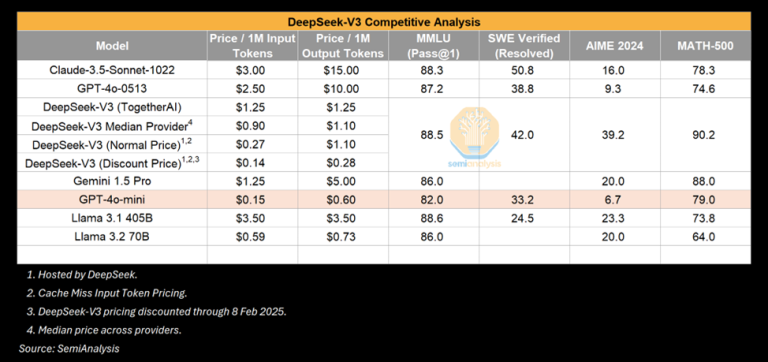
Googleの推論モデルはR1に匹敵する
R1に対する過剰なまでの宣伝が繰り広げられている一方で、米国の2.5兆ドル企業が1か月前に、より安価な推論モデルをリリースしました。GoogleのGemini Flash 2.0 Thinkingです。このモデルは利用可能であり、APIを介したモデルの文脈長がはるかに長いにもかかわらず、R1よりもかなり安価です。
報告されたベンチマークでは、Flash 2.0 ThinkingはR1を上回っていますが、ベンチマークはすべてを物語っているわけではありません。Googleは3つのベンチマークしか発表していないため、不完全な情報です。それでも、Googleのモデルは強固であり、多くの点でR1に匹敵する一方で、過剰な宣伝は受けていないと考えています。これは、Googleの市場戦略が精彩を欠き、ユーザー体験が劣っているためかもしれませんが、R1は中国の驚きでもあります。
はっきりさせておきたいのは、これらはDeepSeekの素晴らしい業績を損なうものではないということです。資金力があり、動きが速く、賢明で、目的意識の高い新興企業として、DeepSeekはMetaのような大手企業を打ち負かして推論モデルをリリースしているのです。これは称賛に値します。
技術的業績
DeepSeekは、大手ラボがまだ達成できていない技術革新の鍵を解き明かし、その扉を開きました。DeepSeekが発表する改善策は、ほぼ即座に欧米のラボによってコピーされるでしょう。
それでは、これらの改善策とは何でしょうか? アーキテクチャ上の成果のほとんどは、特にV3に関連するもので、これはR1のベースモデルでもあります。それでは、これらの技術革新について詳しく説明しましょう。
トレーニング(事前・事後)
DeepSeek V3は、これまでにない規模でマルチトークン予測(MTP)を利用しており、単一のトークンではなく、次の数個のトークンを予測するアテンション・モジュールが追加されています。これにより、トレーニング中のモデルのパフォーマンスが向上し、推論時には破棄することができます。これは、演算量を抑えつつパフォーマンスを向上させることを可能にしたアルゴリズムの革新の一例です。
トレーニングにFP8の精度を適用するなどの考慮事項もありますが、米国の主要ラボでは、FP8のトレーニングをしばらく前から実施しています。
DeepSeek v3は、異なる専門分野を持つ多数の小規模なエキスパートモデルを組み合わせた1つの大規模なエキスパート・モデルでもあり、創発的行動でもあります。MoEモデルが直面してきた課題のひとつは、どのトークンをどのサブモデル、すなわち「エキスパート」に割り当てるかを決定する方法でした。DeepSeekは、モデルのパフォーマンスを損なうことなく、トークンを適切なエキスパートにバランスよくルーティングする「ゲート・ネットワーク」を実装しました。これは、ルーティングが非常に効率的であることを意味し、モデル全体のサイズに比べ、トレーニング中にトークンごとに変更されるパラメータはわずかです。これにより、トレーニングの効率性が高まり、推論のコストが低く抑えられます。
Despite concerns that Mixture-of-Experts (MoE) efficiency gains might reduce investment, Dario points out that the economic benefits of more capable AI models are so substantial that any cost savings are quickly reinvested into building even larger models. Rather than decreasing overall investment, MoE’s improved efficiency will accelerate AI scaling efforts. The companies are laser focused on scaling models to more compute and making them more efficient algorithmically.
R1に関しては、堅牢なベースモデル(v3)があったことが非常に有益でした。これは、部分的に強化学習(RL)によるものです。RLでは、フォーマット(一貫した出力を保証する)と有用性および無害性(モデルが有用であることを保証する)の2点に重点が置かれていました。推論能力は、合成データセット上でモデルを微調整する過程で現れました。これは、当社のスケーリング法に関する記事で言及したように、o1で起こったことです。R1論文では計算量について言及されていませんが、これは使用された計算量について言及すると、彼らの説明よりも多くのGPUを使用していることが明らかになってしまうからです。この規模でのRLには、特に合成データの生成にはかなりの計算量が必要です。
さらに、DeepSeekが使用したデータの一部はOpenAIのモデルからのデータであるようです。そして、これは出力からの蒸留に関するポリシーに影響を及ぼすことになるでしょう。これはすでに利用規約上では違法ですが、今後は蒸留を阻止するためのKYC(Know Your Customer)のような新たな傾向が生まれるかもしれません。
2025年 AI普及 輸出規制 – Microsoftの規制対応、Oracleの涙、定量化された影響、モデル制限
ディラン・パテル、ダニエル・ニッシュボール、マイロン・シェイ、AJ・クラビ、ジェレミー・エリアフ・オンティベロス、レイク・クヌッツェン、イヴァン・チャム
また、蒸留について言えば、R1論文で最も興味深かったのは、推論モデルの出力で微調整を行うことで、推論モデルではない小規模なモデルを推論モデルに変えることができた点でしょう。データセットのキュレーションには合計80万のサンプルが含まれており、今では誰でもR1のCoT出力を使用して独自のデータセットを作成し、その出力の助けを借りて推論モデルを作成することができます。今後は、より多くの小規模モデルが推論能力を発揮し、小規模モデルのパフォーマンスを強化するようになるかもしれません。
マルチヘッド潜在アテンション(MLA)
MLAは、DeepSeekの推論価格を大幅に削減する重要なイノベーションです。その理由は、MLAは標準的なアテンションと比較して、クエリごとに必要なKVキャッシュの量を約93.3%削減するからです。KVキャッシュは、会話の文脈を表すデータを保存し、不要な計算を削減する、トランスフォーマーモデルのメモリメカニズムです。
スケーリング法則の記事で説明したように、会話のコンテクストが増えるにつれ、KVキャッシュも増大し、かなりのメモリ制約が生じます。クエリごとに必要なKVキャッシュの量を大幅に減らすことで、クエリごとに必要なハードウェアの量が減り、コストも削減されます。しかし、DeepSeekは市場シェアを獲得するためにコストをかけて推論を提供しているだけで、実際には利益を上げていないと私たちは考えています。Google Gemini Flash 2 思考は依然として安価であり、Googleがコストをかけて提供しているとは思えません。MLAは特に米国の主要ラボの注目を集めました。MLAは2024年5月にリリースされたDeepSeek V2でリリースされました。DeepSeekはH100と比較してメモリ帯域幅と容量が向上したため、H20では推論処理の効率がさらに向上しました。Huaweiとの提携も発表されましたが、Ascendコンピューティングではこれまでほとんど何も行われていません。
最も興味深い影響は、特にマージンに現れると考えており、それがエコシステム全体にどのような意味を持つのかを考えてみます。以下では、AI業界全体の将来の価格構造について考え、DeepSeekがなぜ価格を吊り下げていると考えられるのか、また、なぜJevonsのパラドックスが現実のものとなる兆しが現れていると考えるのかを詳しく説明します。輸出規制への影響、中国共産党がDeepSeekの支配力を強めた場合にどのような反応を示す可能性があるか、などについても言及します。


コメント